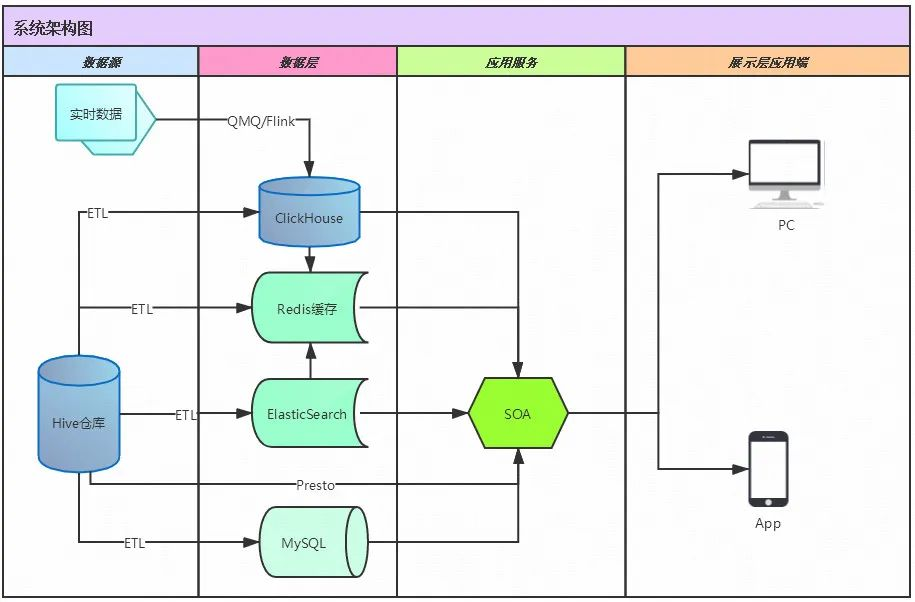
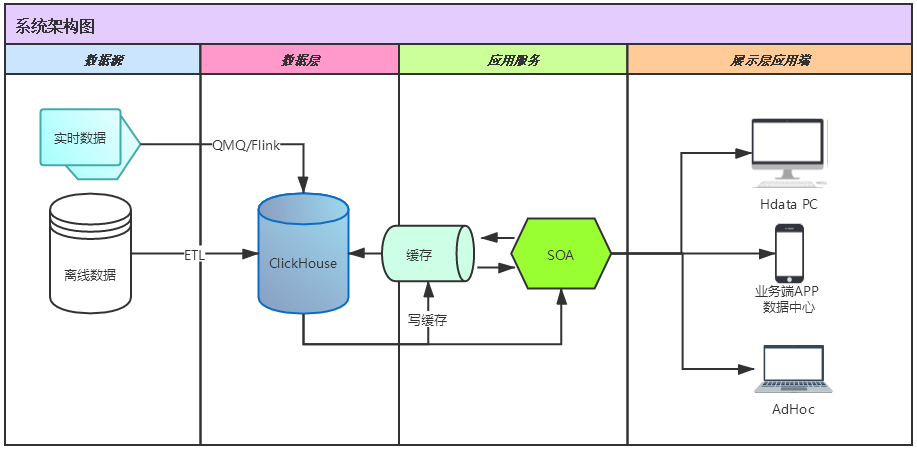
亿级单表数据检索优化
ClickHouse 是一个用于联机分析处理(OLAP)的列式数据库管理系统(DBMS)。它由俄罗斯 IT 公司 Yandex 开发,为了高速查询性能和效率而设计;非常擅长处理大规模数据仓库的快速读取操作。
它提供了以下特点,以支持大规模数据的快速检索:
- 列式存储:优化了聚合查询的性能。
- 数据压缩:减少物理存储需求,提高IO效率。
- 向量化查询执行:提升了计算速度。
- 实时视图(Materialized Views):可以用来存储预计算的聚合数据。
核心功能介绍
- 高性能
- 列式存储: 数据以列的形式存储,能够更快地进行聚合运算,尤其是在不需要所有数据列的查询中。
- 向量化查询执行: ClickHouse 使用向量化查询执行,可同时处理数据的多个值,从而显著提高性能。
- 数据压缩: 列式存储允许高效的数据压缩,节省存储空间,同时加快数据读取速度。
- 可伸缩性
- 分布式处理: ClickHouse 支持分布式数据库架构,可以扩展到多个节点,进行横向扩展。
- 复制: 支持数据在多个节点之间的复制,确保数据的高可用性和容错能力。
- 实时性
- 实时查询处理: ClickHouse 为实时数据分析提供了强大支持,可以快速对实时更新的数据执行查询。
- 流数据处理: 支持流式插入,允许不断地将数据流入数据库,同时进行分析。
- 灵活的数据分析功能
- 多种索引: 支持多种索引类型,如全文搜索索引、n-gram 索引等,以优化各种查询。
- 丰富的数据分析函数: 提供了丰富的内置函数,如聚合函数、数组处理函数、字符串函数等。
- 易用性
- SQL 接口: ClickHouse 支持标准的 SQL 查询语言,对于熟悉 SQL 的用户来说非常友好。
- 兼容性: 支持多种数据格式的输入输出,如 CSV、JSON、Parquet 等,便于与其他系统集成。
- 用户和权限管理: 提供灵活的用户和权限管理功能,确保数据安全。
- 可靠性和容错性
- 数据复制与分片: 支持异步多副本数据复制,以及数据自动分片,提高数据的可靠性和可访问性。
- 容错性: 能够处理节点故障,自动恢复数据,保证服务的持续可用。
- 可定制和扩展性
- 用户定义函数 (UDF): 允许开发者创建自定义函数来扩展数据库的功能。
- 插件架构: 支持通过插件来扩展系统功能。
- 生态系统和集成
- 官方客户端和图形界面: 提供了命令行客户端和图形化界面,方便用户操作和管理。
- 集成: 可以与各种数据导入和导出工具、数据可视化工具以及ETL工具集成。
性能优化
CK使用优化
- 数据分区:合理的数据分区可以大幅提高查询效率,尤其是对于范围查询和过滤。确保按照查询模式来设计分区键。
- 索引:ClickHouse 提供了多种索引类型,包括主键索引和辅助索引如SKIPLIST、ngram等。合理使用索引可以加速查询。
- 物化视图:预计算常见的聚合查询并将结果存储在物化视图中,这样可以直接查询预计算结果而不是原始数据,提升查询速度。
- 数据架构与模型
- 数据去规范化:为了提高查询性能,可以适当去规范化数据模型,将需要联合查询的数据预先合并到一张宽表中。
- 冷热数据分离:将不常查询的冷数据与热数据分离开,放在不同的存储介质上,这样可以优化存储成本并提高热数据的查询效率。
- 查询性能优化
- 精简查询字段:只查询需要的字段,减少数据传输和处理的开销。
- 避免复杂的JOIN操作:尽可能减少在查询中使用复杂的JOIN操作,这些操作通常是性能瓶颈。
- 使用批量插入:当需要插入数据时,批量插入可以减少I/O开销和网络开销。
系统与硬件优化
- 资源分配:确保ClickHouse实例有足够的CPU、内存和I/O资源来处理查询。
- 使用SSD:对于存储介质,使用SSD可以提供更快的读写速度,特别是在随机读写密集的场景下。
分割数据
- 历史数据与实时数据分离:将历史数据(非当日)与实时数据分开处理是个好策略。历史数据通常不会改变,可以预计算聚合并存储在物化视图中。实时数据可以保持在一个单独的表中以支持快速的更新和查询。
- 分区:在ClickHouse中,应该利用分区来管理数据。通过选择合适的分区键,可以将数据分散到不同的分区,这样查询时可以跳过不相关的分区,提高查询效率。
- 分片:对于非常大的数据集,可以考虑分片,即将数据分布在不同的ClickHouse节点上。这可以进一步提高查询性能,因为可以并行查询多个分片。
索引和数据模型优化
- 索引:合理使用索引可以大大提高检索性能。ClickHouse提供了多种索引类型,如主键索引、二级索引等。
- 数据模型优化:根据查询模式优化数据模型,如适当的星形或雪花模型,可以提高查询效率。
- 物化列:如果有某些经常计算的表达式,可以将其作为物化列存储起来。
缓存策略
- 结果缓存:对于经常执行的查询,可以缓存结果集,以便快速响应。
- 预聚合:对于统计管理查询,可以预先计算并存储常见的聚合结果。
- 查询缓存:对于那些不经常变化的查询结果,可以使用Redis等缓存系统来存储,以便快速响应重复的查询请求。
- 前端缓存:如果数据在一段时间内不会变化,可以在应用层面实现缓存,比如使用CDN或本地缓存。
查询优化
- 查询优化:编写高效的SQL查询,避免不必要的计算和数据扫描。
- 异步处理:对于一些耗时的统计任务,可以采用异步处理,例如,通过后台任务预先计算好,然后查询时直接读取结果。
监控和调优
- 监控:定期监控查询性能,分析慢查询,找出瓶颈进行优化。
- 调优:根据监控结果和系统运行情况调整系统配置和资源分配,例如,增加CPU、内存或者调整ClickHouse的配置参数。
最佳实践
ClickHose 使用
- 物化视图(Materialized Views):
- 利用物化视图保存聚合数据。这些视图会在数据插入时自动更新,使得复杂的聚合查询可以即时返回结果。
- 可以为不同的查询或报表需求创建多个物化视图。
- 数据去规范化:
- 在宽表中预先组合来自不同表的数据,以避免在查询时进行昂贵的JOIN操作。
- 索引优化:
- ClickHouse 的主键索引不仅用于维护数据的唯一性,还用于加速查询。选择适当的列作为主键可以大大提高查询效率。
- 使用副本索引(如Bloom Filter索引)来加速特定类型的查询。
- 分区和分片:
- 根据查询模式和数据访问模式,选择合适的分区键,使得查询能够仅扫描相关分区。
- 水平分片可以将数据分散到多个节点上,分布式查询可以并行处理,从而提高查询性能。
- 内存管理:
- 确保有足够的内存用于ClickHouse的缓存,特别是Mark Cache和Data Cache。
- 调整
max_bytes_before_external_group_by和max_bytes_before_external_sort参数,以控制内存使用并防止大查询导致的OOM(内存不足)。
- 查询优化:
- 避免SELECT *,只选择需要的列。
- 使用WHERE过滤条件来减少扫描的数据量。
- 适当时使用
PREWHERE子句,该子句在WHERE之前执行,可以进一步减少需要处理的数据量。
监控与维护
- 监控:
- 利用ClickHouse自带的监控工具,如
system数据库下的多个监控表来跟踪查询执行和系统性能。 - 可以使用外部工具如Grafana配合Prometheus监控ClickHouse的性能指标。
- 利用ClickHouse自带的监控工具,如
- 定期维护:
- 定期执行OPTIMIZE TABLE命令合并数据分区,减少数据
其他数据服务
除了ClickHouse,还可以考虑以下一些数据服务:
- Amazon Redshift:AWS的数据仓库服务,适用于大规模数据集的分析。
- Google BigQuery:无服务器的、高度可扩展的数据仓库,适合大数据分析。
- Apache Druid:面向实时分析的分布式数据存储。
一些案例