LLM-D:分布式推理架构介绍(一)
最近在学习和研究 LLM-D,作为 Cloud-Native 和 LLM-Infra 从业者对于类似新兴技术一直比较敏感,接下来打算以几篇文章来分享下我的学习过程。
- LLM-D 项目介绍 (本文)
- LLM-D 上手指南
- LLM-D 组件介绍
- LLM-D 开源贡献参与
真的学不过来,这篇文章完成用了一周...
写在前面的话
项目定位
LLM-D 是由 Red Hat、 CoreWeave、Google Cloud、NVIDIA、IBM Research 等联合推出的基于 Kubernetes 原生分布式推理框架,旨在解决大规模生成式 AI 模型推理中的高成本、高延迟问题,其目标是将生产级 AI 推理能力标准化。
大模型推理的核心问题与挑战
- 算力需求的结构性转变:推理在生产环境中占比持续增长,引申出对高效推理架构迫切需求;推理优化目前非常火热,并且看起来还有很大的优化空间。
- 集中式推理瓶颈:模型规模还在持续扩大,导致资源需求激增,传统架构面临成本过高、延迟过长问题,优化成本是关键。
- 企业落地难点:需平衡性能(SLO)、成本(TCO)与异构环境兼容性(尤其是国产化的大背景下)。
LLM-D 核心架构与技术特性
理解推理的本质差异
首先,我们要理解 LLM 推理本质上是一个两阶段过程,每个阶段有截然不同的计算特征:
Phase 1: Prefill(预填充)
- 计算特征:O(n²) attention 计算,计算密集型
- 内存模式:顺序写入KV cache
- 硬件需求:高FLOPS(如H100: 989 TFLOPS)
- 典型耗时:100-500ms(8K context)
Phase 2: Decode(解码)
- 计算特征:O(n) attention 计算,内存密集型
- 内存模式:大量KV cache读取
- 硬件需求:高带宽(如L4: 300GB/s)
- 典型耗时:30-50ms/token- Prefill 阶段:处理 prompt,生成 KV Cache,属于计算密集型(compute-bound),主要影响(TTFT)
- Decode 阶段:基于 KV Cache 逐步生成输出 token,属于内存带宽敏感型(memory-bound),主要影响 TPOT)
传统架构将这两个阶段绑定在同一 GPU 上执行,导致严重的资源错配。
LLM 分层架构设计
graph TB
A[客户端请求] --> B(Endpoint/API网关)
B --> C{Inference Scheduler}
C -->|EPP协议路由| D[Prefill Pod]
C -->|缓存感知路由| E[Decode Pod]
D -->|RDMA传输KV缓存| E
E -->|流式输出| B
F[分布式KV缓存管理器] --> D & E
G[K8s控制器] --> C & D & E关键组件
Inference Scheduler (推理调度器)
Inference Scheduler 不是简单的请求负载均衡器,而是深入理解推理过程的智能负载调度器,主要能力包含:
- 动态任务分配:根据请求类型(Prefill/Decode)调用 EPP 协议(Endpoint Picker Protocol)选择最优节点。
- 资源感知调度:基于节点负载、KV 缓存命中率、硬件特性(GPU 算力/ 内存带宽)动态评分。
- 阶段解耦:分离计算密集型预填充(Prefill)与内存密集型解码(Decode),支持独立扩缩容。
# 核心代码
class InferenceScheduler:
def route_request(self, request):
# 1. 请求特征分析
prompt_tokens = tokenizer.encode(request.prompt)
expected_output = self.predict_output_length(prompt_tokens)
# 2. 缓存命中率预测
cache_hit_rate = self.cache_analyzer.predict_hit_rate(
prompt_tokens[:512] # prefix分析
)
# 3. EPP协议评分
prefill_scores = {}
for node in self.prefill_nodes:
score = self.epp_score(
node_load=node.current_load,
cache_affinity=cache_hit_rate[node.id],
network_distance=self.get_latency(node),
gpu_memory_available=node.free_memory
)
prefill_scores[node] = score
# 4. 选择最优节点
best_prefill = max(prefill_scores, key=prefill_scores.get)
# 5. 预分配decode资源
decode_node = self.reserve_decode_node(
expected_tokens=expected_output,
sla_requirements=request.sla
)
return best_prefill, decode_nodePrefill/Decode Pod (PD 分离)
正如前面所说,当前 PD 混合不能很好的发挥硬件性能,LLM-D 定义了分布式推理框架设计(Distributed Inference),将推理过程拆成两个独立部署的工作负载(Pods):
apiVersion: llm-d.ai/v1
kind: InferenceCluster
metadata:
name: llama-70b
spec:
model:
name: meta-llama/Llama-2-70b-chat
quantization: fp16
prefill:
replicas: 4
hardware:
gpu: nvidia.com/gpu-a100-80gb
count: 2
optimization:
flashAttention: v2
fusedKernels: true
decode:
replicas: 16
hardware:
gpu: nvidia.com/gpu-l4-24gb
count: 1
optimization:
pagedAttention: true
kvCompression: 0.5
transport:
protocol: nixl
backend: rdma
bandwidth: 200Gbps
cache:
type: distributed
backend: lmcache
capacity: 2TB
eviction: lru
tiering:
- type: gpu
capacity: 320GB
- type: cpu
capacity: 1TB
- type: nvme
capacity: 10TB| 组件 | 功能 | 优化方向 |
|---|---|---|
| Prefill Pod | 处理完整提示词,生成首 Token 及 KV 缓存 | 高算力 GPU(如 H100、A100) |
| Decode Pod | 基于 KV 缓存流式生成后续 Token | 高内存带宽硬件(如专用推理加速器) |
| Transport | 负责在 Prefill 与 Decode Pod 之间传递 KV Cache,以支持阶段分离和缓存共享 | |
| Cache | 用于存储、复用和调度 KV Cache,提升推理效率与吞吐,同时减少重复计算 |
- 在 Prefill 生成 KV 缓存后,需通过 RDMA/NVLink 或 NIXL 高性能传输库毫秒级传输至 Decode 节点 (对网络性能要求很高)
- llm-d 借助 vLLM 的可插拔 KV Connector API 实现 Prefill 与 Decode 之间的 KV Cache 传递
EPP 协议
Inference Scheduler 提供了一个“端点选择器(EPP)”组件,通过这种方式将传入的推理请求调度合适节点上,实现了智能后端选择 Pods 的能力。
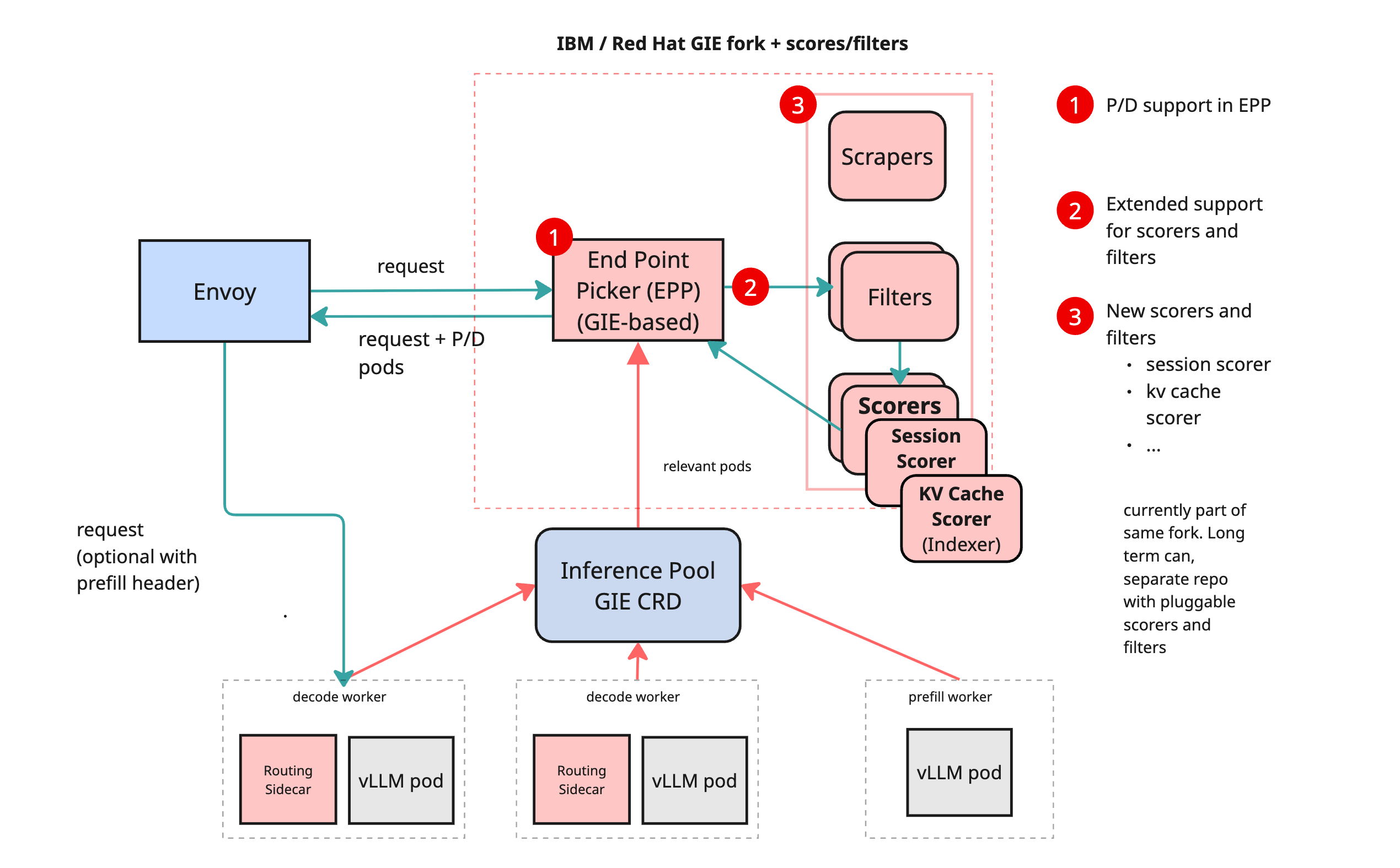
EPP 是 GIE 中插件化路由接口协议,通过它可以自定义过滤器(filters)和打分器(scorers), LLM-D 借此接口将其调度逻辑集成进 GIE,利用了 GIE 的可插拔架构,将其作为推理调度的入口。
GIE(Gateway API Inference Extension) 是针对 AI/LLM 推理流量设计的 Kubernetes Gateway API 扩展, 集成了对模型路由、前缀缓存感知(prefix-cache-aware routing)、服务优先级等调度逻辑的支持。
LLM-D 会收集来自 vLLM 的运行时数据(如哪些 KV cache 在哪个实例缓存?、各实例负载情况? 等),据此实施过滤与打分,从而动态决策请求的最终路由目标。
EPP(Endpoint Picker Protocol)的核心评分算法:
Score = α * (1 - LoadFactor) +
β * CacheAffinity +
γ * (1 / NetworkLatency) +
δ * MemoryAvailable
其中:
- α = 0.3(负载权重)
- β = 0.4(缓存权重,最重要)
- γ = 0.2(网络权重)
- δ = 0.1(内存权重)https://github.com/llm-d/llm-d-inference-scheduler/blob/main/docs/architecture.md
NIXL 高性能传输层 (Transport)
llm-d 主要在利用 vLLM 的 KVConnector 和 NIXL 构建 PD 分离推理流水线,并嵌入到 Inference Scheduler,实现缓存感知调度。
NIXL(NVIDIA Inference Transfer Library)是 PD 分离的关键底层传输库,负责高速异步地在 GPU 或不同存储层之间移动 KV cache, 主要实现是通过 NixlConnector 与 vLLM 通信将 KV Cache buffer 转移,支持多种硬件互联方式,和自适应选择互联方式,确保传输低延迟与高吞吐。
| 阶段 | 主要职责与组件 |
|---|---|
| Prefill 阶段 | vLLM 使用 KVConnector(如 NixlConnector)输出 KV Cache buffer,可能经过 LMCache 聚合。 |
| 传输层 | NIXL 负责 buffer 的跨实例高效传输,支持多种硬件互连方式。 |
| Decode 阶段 | 接收 buffer,恢复 KV Cache,用于后续生成 token。 |
NIXL 一个核心的特点是通过一个多功能 API 提供跨各种内存类型的统一抽象,隐藏了额外的后端细节,如连接管理、寻址方案和内存特性等,简化了使用成本。
https://github.com/ai-dynamo/nixl > https://github.com/ai-dynamo/nixl/blob/main/docs/nixl.md
3. LMCache 分布式缓存系统
LMCache 提供了多级缓存架构,在 vLLM 生成上下文 KV Cache 之后,LMCache 能有效缓存这些 KV。 动态选择缓存位置包括 GPU 显存、主机内存(DRAM)、本地磁盘,甚至远程存储,从而减少重复计算所需的 GPU 周期。
目前 LMCache 已成为 llm-d 默认的 KV Cache 层,负责缓存、复用并跨硬件/ 实例传递 KV Cache。
class LMCache:
def __init__(self):
self.cache_hierarchy = [
GPUCache(capacity="320GB", latency="100ns"),
CPUCache(capacity="1TB", latency="100μs"),
NVMeCache(capacity="10TB", latency="10ms"),
S3Cache(capacity="unlimited", latency="100ms")
]
def get(self, key, tokens_needed):
# 1. 计算缓存查找策略
for cache_tier in self.cache_hierarchy:
if cache_tier.contains(key):
# 2. 判断是否需要提升到更快的层级
if self.should_promote(key, cache_tier):
self.promote_to_faster_tier(key, cache_tier)
# 3. 异步预取可能需要的后续块
self.prefetch_adjacent_blocks(key, tokens_needed)
return cache_tier.get(key)
return None # Cache miss
def put(self, key, value):
# 智能决定存储层级
tier = self.select_tier_by_access_pattern(key)
tier.put(key, value)
# 异步复制到下级存储
self.async_replicate_to_lower_tiers(key, value, tier)核心特色:
| 阶段 / 功能 | 作用 |
|---|---|
| Prefill 后缓存存储 | 持久化 KV Cache,放入 GPU、DRAM、磁盘、远程存储等多个层级 |
| 缓存复用(多轮对话) | 避免重复计算 KV Cache,提高响应速度和资源利用效率 |
| 分布式 Prefill 与 Decode | 与 vLLM 的 KVConnector 和 NIXL 协作,实现高效缓存传输和阶段分离 |
| 非前缀缓存支持 | 提高多轮对话或上下文复杂场景中的命中率 |
核心优化
| 技术 | 效果 | 适用场景 |
|---|---|---|
| 前缀缓存感知路由 | TTFT(首 Token 时间)大幅降低 | 高 SLO 要求的实时交互 |
| 变体自动扩缩(Variant Autoscaling) | 按需伸缩 Prefill/Decode 组,有效控制成本 | 流量波动大的生产环境 |
Prefix Cache 感知路由
通过分析请求的 prefix 相似度,智能路由到缓存命中率最高的节点:
def prefix_aware_routing(request, nodes):
# 提取前512 tokens作为prefix signature
prefix = request.tokens[:512]
prefix_hash = hash(prefix)
# 查询各节点的缓存状态
cache_stats = []
for node in nodes:
hit_rate = node.cache_bloom_filter.estimate_hit_rate(prefix_hash)
cache_stats.append({
'node': node,
'hit_rate': hit_rate,
'saved_compute': hit_rate * len(prefix) * ATTENTION_FLOPS
})
# 选择收益最大的节点
best_node = max(cache_stats, key=lambda x: x['saved_compute'])
# 如果命中率>80%,TTFT可降低70%
if best_node['hit_rate'] > 0.8:
estimated_ttft = BASE_TTFT * 0.3
else:
estimated_ttft = BASE_TTFT
return best_node['node'], estimated_ttft变体自动扩缩(Variant Autoscaling)
根据工作负载特征动态调整 Prefill/Decode 配比:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: llm-d-autoscaler
spec:
scaleTargetRef:
apiVersion: llm-d.ai/v1
kind: InferenceService
name: production-service
minReplicas:
prefill: 2
decode: 4
maxReplicas:
prefill: 10
decode: 40
metrics:
- type: Custom
custom:
metric:
name: prefill_queue_depth
target:
type: Value
value: 10 # 队列深度超过10则扩容
- type: Custom
custom:
metric:
name: decode_token_latency_p95
target:
type: Value
value: 50ms # P95延迟超过50ms则扩容
behavior:
scaleUp:
policies:
- type: Percent
value: 100 # 快速扩容,每次翻倍
periodSeconds: 15
scaleDown:
policies:
- type: Percent
value: 10 # 缓慢缩容,每次减10%
periodSeconds: 300主流推理框架对比
| 特性 | LLM-D | vLLM | TensorRT-LLM | SGLang |
|---|---|---|---|---|
| P/D 解耦 | ✅ 原生支持 | ⚠️ 实验性 | ❌ | ⚠️ 部分 |
| 分布式 KV Cache | ✅LMCache | ❌ | ❌ | ⚠️ 有限 |
| K8s 原生 | ✅CRD+Operator | ⚠️ 需要额外配置 | ❌ | ❌ |
| 异构硬件 | ✅CPU+GPU 混合 | ⚠️ 主要 GPU | ❌ 仅 NVIDIA | ⚠️ |
| 智能路由 | ✅EPP 协议 | ❌ | ❌ | ⚠️ 基础 |
| 缓存感知调度 | ✅ 原生 | ⚠️ 手动 | ❌ | ❌ |
总结与趋势展望
LLM-D 在技术上的亮点:PD 分离、缓存感知路由、云原生化的核心特色,为大模型推理带来新的推理优化思路,同类的项目也是非常多,足见大模型推理还是有很长的路要走。
当然,LLM-D 目前发展还在早期;从长远角度来看,推动 AI 推理从“集中式单点优化”转向“分布式标准化基建”,对未来的自动并行与安全协作方向也具备很高潜力,是值得关注和参与的开源基础设施项目。
- 👉 项目主页:https://llm-d.ai
- 👉 GitHub 仓库:https://github.com/llm-d/llm-d