NVIDIA Dynamo
最近深入研究大模型推理优化时,NVIDIA 推出的 Dynamo 框架给了我不少惊喜。经过几个月的实际测试和源码分析,想和大家分享一些深度的技术洞察。
NVIDIA Dynamo 是一个专为生成式 AI 和推理模型设计的高吞吐、低延迟推理框架。它的设计哲学很有意思:不是要替代 TensorRT-LLM、vLLM 或 SGLang,而是作为一个"智能调度层",通过 分离式推理(Disaggregated Inference)、KV-aware 智能路由、动态 GPU 调度 和 NIXL 高速数据传输 来最大化整个分布式集群的效率。
从技术栈来看,Dynamo 采用了 Rust(核心性能)+ Python(扩展性)的混合架构, Rust 保证了分布式运行时的性能和安全性,Python 则提供了良好的生态兼容性。
目前最新的 v0.5.0 版本(2025 年 9 月 24 日)性能数据很亮眼:
- 单节点 30% 吞吐量提升
- 双节点配置超过 2 倍性能提升
- KV-aware routing 带来 3 倍 TTFT 改进
- 系统内存卸载实现 40% TTFT 提升
兼容性
在生产环境部署前,有几个关键约束需要注意:
- 平台支持:x86_64 Linux 为主要目标,ARM64 仍处于实验阶段,建议暂缓生产使用
- 发行版兼容:Ubuntu 22.04/24.04 经过完整验证,基于 manylinux_2_28 glibc 基准
- Python 版本依赖:KVBM 功能强制要求 Python 3.12,目前仅在 Ubuntu 24.04 上达到生产稳定性
- 容器生态:NGC 提供全套预编译镜像,涵盖 vLLM/SGLang/TRT-LLM 运行时和完整的 K8s Operator/Helm Charts
核心架构:分离式推理
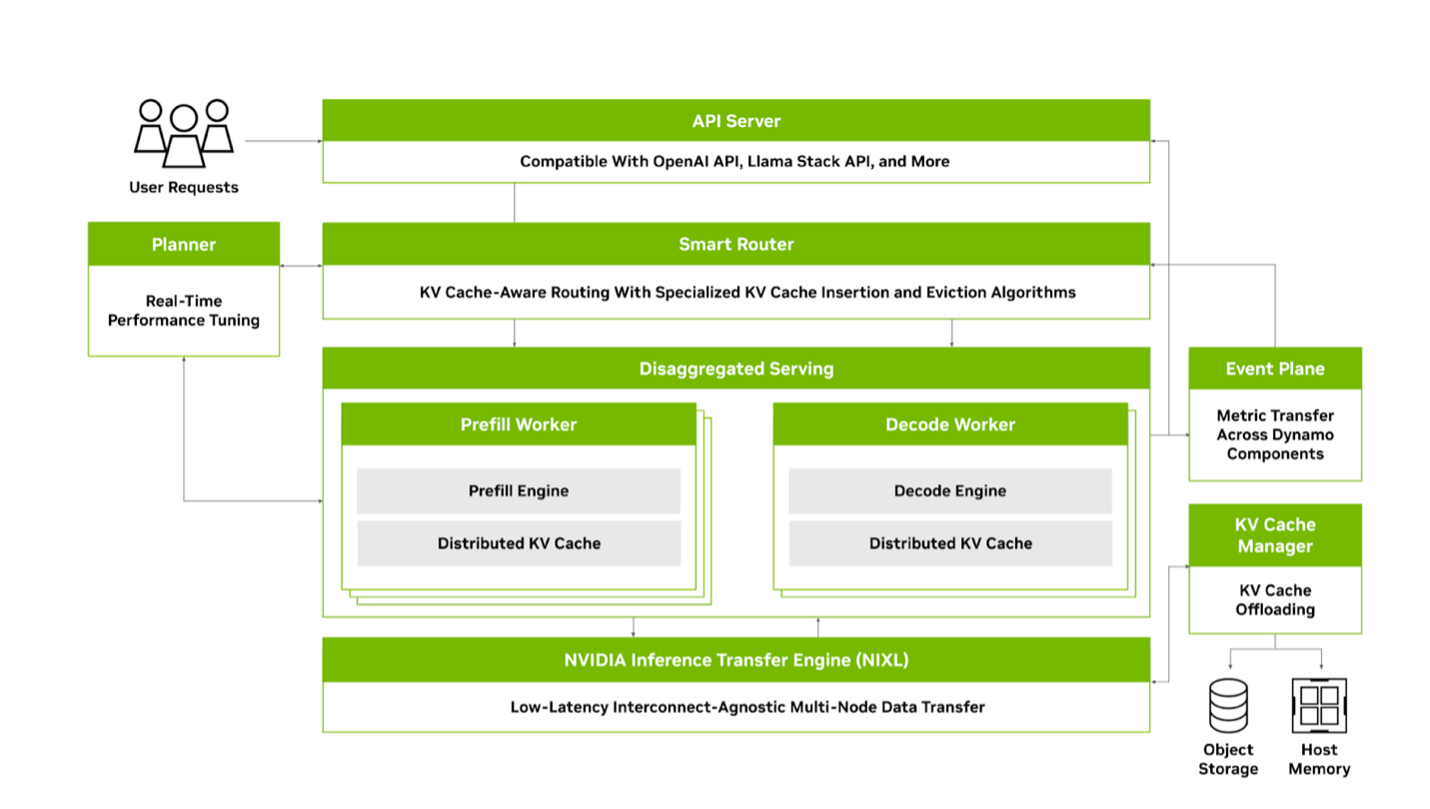 官方架构图展示了各组件如何协同工作
官方架构图展示了各组件如何协同工作
分离式推理的技术内核
传统 LLM 推理把 prefill 和 decode 绑定在同一个 GPU 上,但这两个阶段的计算特征截然不同:
Prefill 阶段(计算密集型):
- O(n²) attention 计算复杂度
- 顺序写入 KV cache
- 需要高 FLOPS(如 H100 的 989 TFLOPS)
- 主要影响 TTFT(Time To First Token)
Decode 阶段(内存密集型):
- O(n) attention 计算复杂度
- 大量 KV cache 读取操作
- 需要高内存带宽(如 L4 的 300GB/s)
- 主要影响 ITL(Inter-Token Latency)
Dynamo 的分离式架构通过 条件分离策略 来动态决定:
- 当 prefill 长度超过预设阈值时
- 当 prefill 队列中请求数少于预设值时
系统会将 prefill 任务路由到专门的 prefill worker,完成计算后通过 NIXL 进行非阻塞的 KV cache 传输。
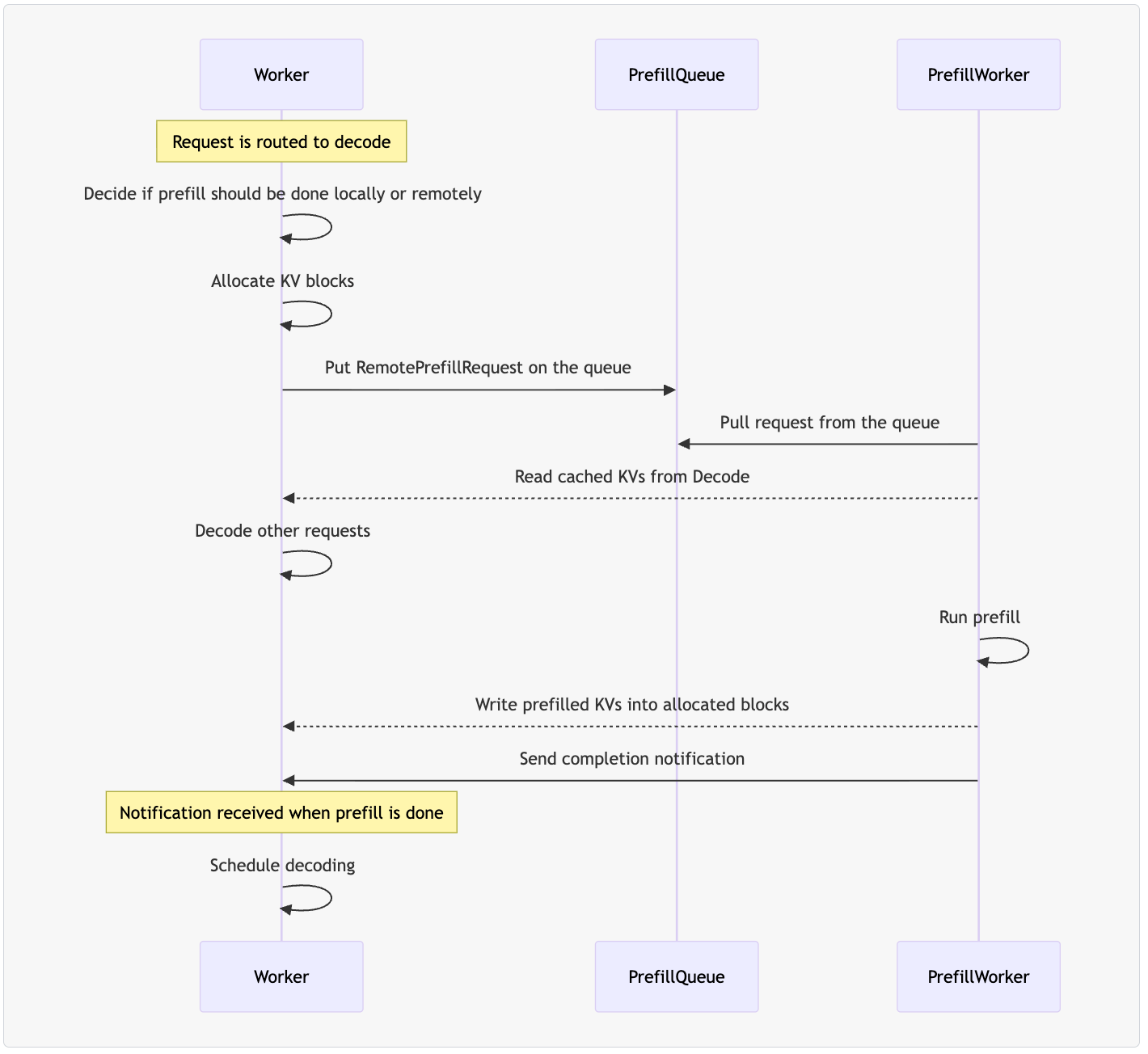 展示了 prefill 和 decode 分离后的完整执行流程
展示了 prefill 和 decode 分离后的完整执行流程
核心组件
Frontend(前端网关):
- 提供 OpenAI 兼容的 HTTP/gRPC 接口
- 负责请求验证、预处理和负载均衡
- 支持独立水平扩缩容,与路由逻辑解耦
KV Router(智能路由引擎): 这是整个系统的"大脑",使用了一个很精妙的成本计算算法:
logit = kv_overlap_score_weight × potential_prefill_blocks + potential_active_blocks- 维护全集群的 KV block 索引(基于 16 或 64 token 的固定块大小)
- 使用 Softmax 采样算法选择最优 worker
- 支持实时 KV 事件跟踪模式和近似模式两种运行方式
- 通过调整
kv-overlap-score-weight参数来优化不同工作负载
KVBM(三层存储架构): 这个组件的设计很有意思,采用了清晰的三层架构:
上层:LLM 推理运行时(TRT-LLM/vLLM/SGLang)
- 通过专用连接器模块与 KVBM 接口
- 提供运行时特定的块导向内存接口转换
中层:KVBM 核心
- 管理块内存作为运行时基底
- 处理表查找、内存分配、块布局管理
- 实现生命周期、状态转换和块重用/驱逐策略
底层:NIXL(网络和存储集成层)
- 支持 P2P GPU 传输和远程内存共享
- 多存储后端:GPU HBM ↔︎ 主机 DRAM ↔︎ 远程 DRAM ↔︎ NVMe/对象存储
Planner(动态调度器): 支持两种智能调度模式:
- 负载型调度:监控 KV cache 利用率和 prefill 队列大小
- SLA 型调度:使用预测建模和性能插值,主动确保 TTFT 和 ITL 目标
当前版本主要支持 vLLM 后端的优雅缩容(零请求丢失),TRT-LLM 和 SGLang 的支持还在完善中。
性能基准与调优要点
我在测试中发现几个关键的调优点:
- TRT-LLM + NIXL KV 传输仍标记为实验性,建议充分压测后再上生产
- WEKA 实验室的数据 显示,通过 NIXL 插件可实现接近内存速度的 KV 流传输,从存储读取 KV 时能显著降低 TTFT 并提升吞吐量
- Router 温度参数 需要根据工作负载特征调整,避免 worker 饱和度不均
快速上手
Dynamo 是一套完全基于 Kubernetes 的云原生分布式推理框架,在 Kubernetes 实验挺方便的。
Kubernetes 部署
实际体验下来,NVIDIA 提供的 Kubernetes 部署方案已经相当成熟,支持完整的 GitOps 工作流:
# 1) CRD 和平台组件安装
export NAMESPACE=dynamo-production
export RELEASE_VERSION=0.5.0
# 安装 CRDs 和 Chart
helm fetch oci://nvcr.io/nvidia/ai-dynamo/charts/dynamo-crds --version ${RELEASE_VERSION}
helm install dynamo-crds ./dynamo-crds-${RELEASE_VERSION}.tgz --namespace default
# 创建 Namespace 并安装
kubectl create namespace ${NAMESPACE}
helm fetch oci://nvcr.io/nvidia/ai-dynamo/charts/dynamo-platform --version ${RELEASE_VERSION}
helm install dynamo-platform ./dynamo-platform-${RELEASE_VERSION}.tgz \
--namespace ${NAMESPACE} \
--set operator.logLevel=INFO
# 部署示例后端(vLLM aggregated 模式)
kubectl apply -f - <<EOF
apiVersion: v1alpha1.dynamo.nvidia.com
kind: DynamoGraphDeployment
metadata:
name: production-vllm
namespace: ${NAMESPACE}
spec:
backend: vllm
model: meta-llama/Llama-2-7b-chat-hf
deployment_mode: aggregated
frontend:
replicas: 2
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
workers:
replicas: 3
resources:
requests:
nvidia.com/gpu: 1
cpu: "4"
memory: "16Gi"
limits:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
EOF
# 监控部署状态
kubectl get dynamographdeployment -n ${NAMESPACE} -w
kubectl describe dynamographdeployment production-vllm -n ${NAMESPACE}
# 服务验证和性能测试
kubectl port-forward svc/production-vllm-frontend 8000:8000 -n ${NAMESPACE}
curl http://localhost:8000/v1/models | jq '.'部署策略建议:
- 开发/测试环境:使用 aggregated 配置,简单快速
- 生产环境:采用 disaggregated 配置,支持独立扩缩容
- 高性能场景:启用 KV-aware routing + KVBM 分层存储
Dynamo Operator
Operator 的设计很巧妙,采用了标准的 Kubernetes CRD + Controller 模式:
核心组件:
DynamoGraphDeploymentController:管理完整的服务图DynamoComponentDeploymentController:处理单个组件的生命周期
GitOps 兼容性:
支持 FluxCD 等工具进行声明式部署,可以通过修改自定义资源来滚动更新整个推理集群。
# 支持版本控制的基础设施即代码
apiVersion: v1alpha1.dynamo.nvidia.com
kind: DynamoGraphDeployment
metadata:
name: llama2-chat-production
spec:
version: "v0.5.0"
backend: vllm
deployment_mode: disaggregated
kvbm:
enabled: true
storage_tiers:
- hbm
- host_dram
- nvme_ssd
planner:
enabled: true
scaling_mode: sla_based
target_ttft_ms: 500
target_itl_ms: 50一些调优技巧
Router 智能路由调优
基于我的实际测试,Router 的参数调优对性能影响很大:
# prefill 重工作负载优化
python -m dynamo.frontend \
--router-mode kv \
--kv-overlap-score-weight 2.0 \ # 增加 prefill 权重
--router-temperature 0.8 \ # 降低随机性
--kv-cache-block-size 64 # 大块大小适合长文本
# decode 重工作负载优化
python -m dynamo.frontend \
--router-mode kv \
--kv-overlap-score-weight 0.5 \ # 降低 prefill 权重
--router-temperature 1.2 \ # 增加随机性防止热点
--kv-cache-block-size 16 # 小块适合短响应KVBM 分层存储配置
# 启用多层存储的 worker 配置
python -m dynamo.sglang.worker \
--model meta-llama/Llama-2-7b-chat-hf \
--connector kvbm \
--kvbm-storage-tiers hbm,host_dram,nvme_ssd \
--kvbm-offload-ratio 0.7 \ # 70% KV cache 可卸载到主机内存
--kvbm-nvme-path /fast-nvme/kv-cache可观测性配置
v0.5.0 统一了各引擎的 Prometheus 指标,支持细粒度监控:
# Grafana Dashboard 关键指标
- name: dynamo_frontend_requests_total
description: 前端请求总数
- name: dynamo_router_kv_cache_hit_ratio
description: KV cache 命中率
- name: dynamo_worker_prefill_latency_ms
description: Prefill 延迟分布
- name: dynamo_kvbm_memory_utilization_percent
description: KVBM 内存使用率
- name: dynamo_planner_scaling_events_total
description: Planner 触发的扩缩容事件版本演进
从技术演进来看,v0.5.0 版本有几个关键改进:
- TRT-LLM KVBM 连接器:虽然还是实验性,但为高性能场景提供了可能
- 端到端请求取消:提升了用户体验,特别是长文本生成场景
- 统一 Prometheus 指标:终于不用为不同引擎配置不同的监控规则了
- KServe gRPC 支持:与企业 MLOps 平台的集成更加顺滑
思考与展望
从技术架构来看,NVIDIA Dynamo 代表了分布式 LLM 推理的一个重要方向。它不是简单的横向扩展,而是从推理过程的本质特征出发,重新设计了计算和存储的分离。
特别值得关注的是 KVBM 的三层架构设计——它不仅解决了当前的内存瓶颈,更为未来的异构存储(包括 CXL 内存、远程 RDMA、对象存储)提供了统一的抽象层。
Router 的智能算法 也很有意思,它实际上在做一个多目标优化:最小化计算成本的同时最大化 cache 复用率。这个成本函数还可能会进一步演进,加入网络延迟、能耗等因素。
从生态角度看,Dynamo 与 Kubernetes 的深度集成(特别是 CRD/Operator 模式)表明了 NVIDIA 对企业市场的重视。这种云原生的设计让它很容易集成到现有的 MLOps 工具链中。
不过也有一些需要持续关注的点:
- TRT-LLM 集成的成熟度:作为 NVIDIA 的亲儿子,这个集成路径的稳定性直接影响高性能场景的采用
- 跨云厂商的兼容性:目前主要在 NVIDIA GPU 环境测试,国产化 GPU 平台还需要探索其他项目
- 社区生态的发展:作为一个相对较新的项目,第三方工具和最佳实践还在积累中
总的来说,NVIDIA Dynamo 是个很有技术深度的项目,特别适合那些对大模型推理有严格性能要求的团队。如果你的场景涉及长上下文、高并发或者成本敏感的推理工作负载,值得深入评估和试用。